notes for my revision, covers:
The main question we are after is How to optimize optimizers using gradient based meta-training in JAX and Why JAX ?
Core abstractions
- Tasks
- Optimizers
- Learned Optimizers
- Outer Trainers
from learned_optimization.outer_trainers import full_es
from learned_optimization.outer_trainers import truncated_pes
from learned_optimization.outer_trainers import gradient_learner
from learned_optimization.outer_trainers import truncation_schedulefrom learned_optimization.tasks import quadratics
from learned_optimization.tasks.fixed import image_mlp
from learned_optimization.tasks import base as tasks_base
from learned_optimization.tasks.datasets import base as datasets_base
from learned_optimziation.learned_optimizers import base as lopt_base
from learned_optimization.learned_optimizers import mlp_lopt
from learned_optimizers.optimizers import base as opt_baseTask abstraction
- Task object is used to specify optimization problem, optimization problem could be another optimization problem, like in case of optimizing optimizers.
- task object creation;
task = image_mlp.ImageMLP_FashinMnist8_Relu32()select a task. - task.init;
params = task.init(key)samples a task, and returns params. We pass key to have control over sampling over task. - task.dataset.train;
batch = next(task.datasets.train) - task.loss;
loss = task.loss(params, key1, batch)notice the arguments here, we pass params, key1 and batch.
Minimal gradient descent in JAX using Task class
A minimal gradient descent optimization of a model in jax using tree_map(lambda p, g: p - 0.1*g, params, grads)) this will be replaced with optimizer api’s, based on optimizer choice the update rule will be changed.
grad_fn = jax.jit(jax.value_and_grad(task.loss))
key = jax.random.PRNGKey(0)
params = task.init(key)
for i in range(10):
key, key1 = jax.random.split(key)
batch = next(task.datasets.train)
l, grads = grad_fn(params, key1, batch)
params = jax.tree_util.tree_map(lambda p, g: p - 0.1*g, params, grads)
if i%100 == 0:
test_l = task.loss(params, key, next(task.datasets.test))key once used will be destroyed, but here test_l and split are getting same key, could be issue.
Optimizers abstraction
tree_map(lambda p, g: p - 0.1*g, params, grads)) will be replaced with optimizer api’s
- No standard interface for optimizers in JAX
- optax is kindof standard optimization library, learned_optimization adds additional inputs to optimizer therefore Optimizers Interface difference in Optax vs Learned_optimization? Few points to understand interface difference b/w optax and learned_optimization.
- Both define stateless optimizers
- both opt.init take params, and return opt_state, each opt_state is different structure.
- opt_state in learned_optimization has params, model_state, opt_state(momentum, etc) and iteration.
- while opt_state in optax has opt_state (momentum, etc), also present above, since general optimizers are independent of parameters.
- while opt.update takes (opt_state, grads, loss) in learned_optimization returns opt_state which will have updated_params, the optax’s opt.update takes (grads, opt_state) returns (update, opt_state), these updates need to be applied on params using optax.apply_updates(updates, params), returns next_params/updated_params.
- optimizer object creation using
opt = opt_base.SGD(1e-4) - opt.init;
opt_state = opt.init(params)returns opt_state which contains params, model_state (model stats) and additional optimizer state such as momentum etc. - opt.update;
next_opt_state = opt.update(opt_state, fake_grads, fake_loss) - opt.get_params
- opt.get_state
task = image_mlp.ImageMLP_FashionMnist_Relu32()
key = jax.random.PRNGKey(0)
params = task.init(key)
opt = opt_base.Adam(1e-2)
opt_state = opt.init(params)
@jax.jit
def update(opt_state, key, batch):
key, key1 = jax.random.split(key)
params, model_state = opt.get_params_state(opt_state)
loss, grads = jax.value_and_grad(task.loss)(params, key1, batch)
opt_state = opt.update(opt_state, grads, loss)
return opt_state, key, loss
for i in range(10):
batch = next(task.datasets.train)
opt_state, key, loss = update(opt_state, key, batch)
print(loss)We could have done next(task.datasets.train) into update function, would it affect jax.jit compile?
- yes, add bb = next(task.datasets.train) inside update, and print bb, you will see bb is not jit tracer object, therefore jax.value_and_grad(task.loss)(params, key1, batch) won’t be optimized for batch argument etc.
Defining a Custom Optimizer
- Optimizer defined as stateless class
- Optimizer state defined using pytree object
import flax
from typing import Any
@flax.struct.dataclass
class MomentumOptState:
params: Any
model_state: Any
iteration: jnp.ndarray
momentums: Anyclass MomentumOptimizer(opt_base.Optimizer):
def __init__(self, lr=1e-3, momentum=0.9):
super().__init__()
self._lr = lr
self._momentum = momentum
def init(self, params, model_state=None, **kwargs):
return MomentumOptState(
params=params,
model_state=model_state,
momentums=jnp.tree_util.tree_map(lambda p : jnp.zeroslike(p), params),
iteration=jnp.asarray(0, dtype=jnp.int32))
def get_params(self, opt_state):
return opt_state.params
def get_state(self, opt_state):
return opt_state.model_state
def update_grad(self, opt_state, grads, loss, model_state=None, **kwargs):
def update_fn(momentum, grad, param):
next_m = momentum*self._momentum + grad*(1-self._momentum)
next_p = param - self._lr*next_m
return next_p, next_m
output_params, output_momentums = jax.tree_util.tree_map(update_fn, opt_state.momentums, grads, opt_state.params)
return MomentumOptState(
params=output_params,
momentums=output_momentums,
iteration = opt_state.iteration+1,
model_state=model_state )
def update(self, opt_state, grads, loss, model_state=None, **kwargs):
struct = jax.tree_util.tree_structure(grads)
flat_momentum = jax.tree_util.tree_leaves(opt_state.momentums)
flat_params = jax.tree_util.tree_leaves(opt_state.params)
flat_grads = jax.tree_util.tree_leaves(grads)
output_params = []
output_momentums = []
for m, g, p in zip(flat_momentum, flat_grads, flat_params):
next_m = m * self._momentum + g * (1 - self._momentum)
next_p = p - self_lr*next_m
output_momentums.append(next_m)
output_params.append(next_p)
return MomentumOptState(
params=jax.tree_util.tree_unflatten(struct, output_params),
momentums = jax.tree_util.tree_unflatten(struct, output_momentums),
iteration = opt_state.iteration+1,
model_state=model_state )
opt = MomentumOptimizer(lr=1)
opt_state = opt.init({"a": 1.0, "b": 2.0})
opt.update(opt_state, {"a": -1.0, "b": 1.0}, 1.0)we have written two approaches of update function, one approach is flattening the tree, calculate the new params, and then unflattening it back again, while other approach is pass update function to the tree_map itself.
Caution
The passing of update function to tree_map won’t work, because tree map is designed to return a single tree. Resulting in the below tree.
{'a': (Array(1.1, dtype=float32, weak_type=True), Array(-0.1, dtype=float32, weak_type=True)), 'b': (Array(1.9, dtype=float32, weak_type=True), Array(0.1, dtype=float32, weak_type=True))}
This line output_params, output_momentums = jax.tree_util.tree_map(update_fn, opt_state.momentums, grads, opt_state.params) will fail to extract things properly.
Learned Optimizers abstraction
- optimizers parameterized by additional set of variables, often called theta.
- learned optimizer object creation
lopt = lopt_base.LearnableAdam() - lopt.init(key);
theta = lopt.init(key)key is create a random initialization. - instance of learned optimizer;
opt = lopt.opt_fn(theta), this opt can be used similar to regular optimizer.
Learnable Adam is adam optimizer with learnable hyperparameters.
lopt = lopt_base.LearnableAdam()
theta = lopt.init(key)
theta
{'log_epsilon': DeviceArray(-18.420681, dtype=float32, weak_type=True),
'log_lr': DeviceArray(-6.9077554, dtype=float32, weak_type=True),
'one_minus_beta1': DeviceArray(-2.3025851, dtype=float32, weak_type=True),
'one_minus_beta2': DeviceArray(-6.9077554, dtype=float32, weak_type=True)}
[Tutorial] gradient based meta training to train learnable adam
The learned_optimization tutorial uses loss at the end of training alone, here we use loss over the training loop. Understood code in the morning, implemented at night only by referencing the core abstractions defined above.
- meta_loss_fn is defined to evaluate the theta (parameters of learned optimizer or parameters which define an instance)
- we take instance of lopt (opt) and use this opt to train a model gives (meta_loss), we can be used to optimize theta, find better instance of lopt.
task = image_mlp.ImageMLP_FashionMnist8_Relu32()
key = jax.random.PRNGKey(0)
lopt = lopt_base.LearnableAdam()
# we want to train this theta using meta_loss, how theta optimizer performs on the task.
@jax.jit
def meta_loss_fn(theta, key, batch, meta_loss):
opt = lopt.opt_fn(theta)
key, key1 = jax.random.split(key)
params = task.init(key1)
opt_state = opt.init(params)
for i in range(4):
params = opt.get_params(opt_state)
key, key1 = jax.random.split(key)
l, grads = jax.value_and_grad(task.loss)(opt_state.params, key1, batch)
# l, grads = jax.value_and_grad(task.loss)(params, key1, batch)
meta_loss += l
opt_state = opt.update(opt_state, grads, l)
params, state = opt.get_params_state(opt_state)
key1, key = jax.random.split(key)
final_loss = task.loss(params, key1, batch)
# final_loss = task.loss(opt_state.params, key1, batch)
return meta_loss
theta_opt = opt_base.Adam(1e-2)
key, key1 = jax.random.split(key)
theta = lopt.init(key1)
theta_opt_state = theta_opt.init(theta)
meta_losses = []
learning_rates = []
meta_value_and_grad = jax.jit(jax.value_and_grad(meta_loss_fn))
for i in range(2000):
batch = next(task.datasets.train)
key, key1 = jax.random.split(key)
theta = theta_opt.get_params(theta_opt_state)
meta_loss = jnp.asarray(0, dtype=jnp.int32)
# ml, meta_grads = meta_value_and_grad(theta, key1, batch, meta_loss)
ml, meta_grads = meta_value_and_grad(theta_opt_state.params, key1, batch, meta_loss)
theta_opt_state = theta_opt.update(theta_opt_state, meta_grads, ml)
meta_losses.append(ml)
learning_rates.append(theta["log_lr"])
if i % 100 == 0:
print(ml)
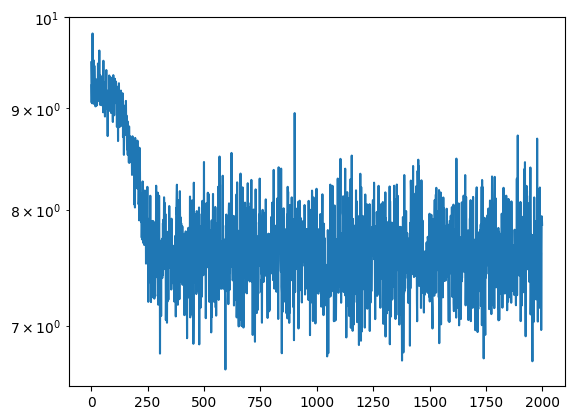
plt.semilogy(meta_losses)
plt.show()
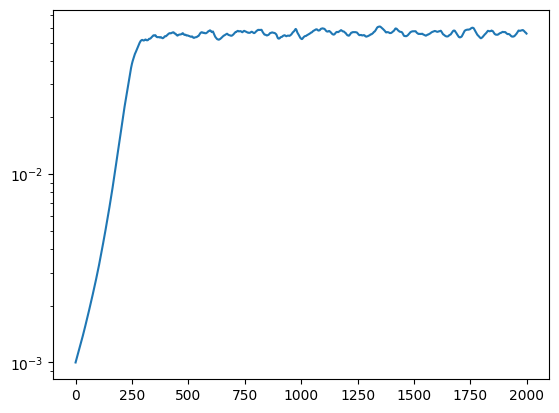
plt.semilogy(np.exp(learning_rates))
plt.show()