Introduction
Many other seemingly distinct Computer Vision tasks (such as object detection, segmentation) can be reduced to image classification.
Image classification is solved through data-driven approach.
Question
Any alternatives other than data-driven approach for Image Classification.
Challenges
Info
Because Computer Vision algorithms take raw representation of images as a 3-D array of brightness values.
Non-exhaustive challenges are:
- Viewpoint variation
- Scale variation
- Deformation
- Occlusion
- Illumination conditions
- Background clutter
- Intra-class variation
Image Classification Pipeline
- Input: A set of N images, each labeled with one of K different classes. [training set]
- Learning: Use the training set to learn what every one of the classes looks like. [training a classifier] or [learning a model]
- Evaluation: Evaluate the quality of classifier on a new set of images that it has never seen before. Predictions should match up with the true answers (which we call ground truth).
Nearest Neighbour Classifier
- It is rarely used in practice.
- Given the training set and test set; find nearest neighbour of each test sample using L1/L2 distance.
- [k-nearest neighbour classifier] Higher values of k have a smoothing effect that makes the classifier more resistant to outliers.
Validation sets for Hyperparameter tuning
- [Validation] Split the training set into training set and validation set. Use validation set to tune all hyperparameters.
- At the end run a single time on the test set and report performance, ie, generalisation.
- [Cross-validation] Split the training set into k-fold, where 1 fold is used as validation set in each turn, and average over all performances on validation sets is used for hyperparameter tuning.
Question
Cross-validation has same different trained model across different validation set selection from the k-fold sets of the training set.

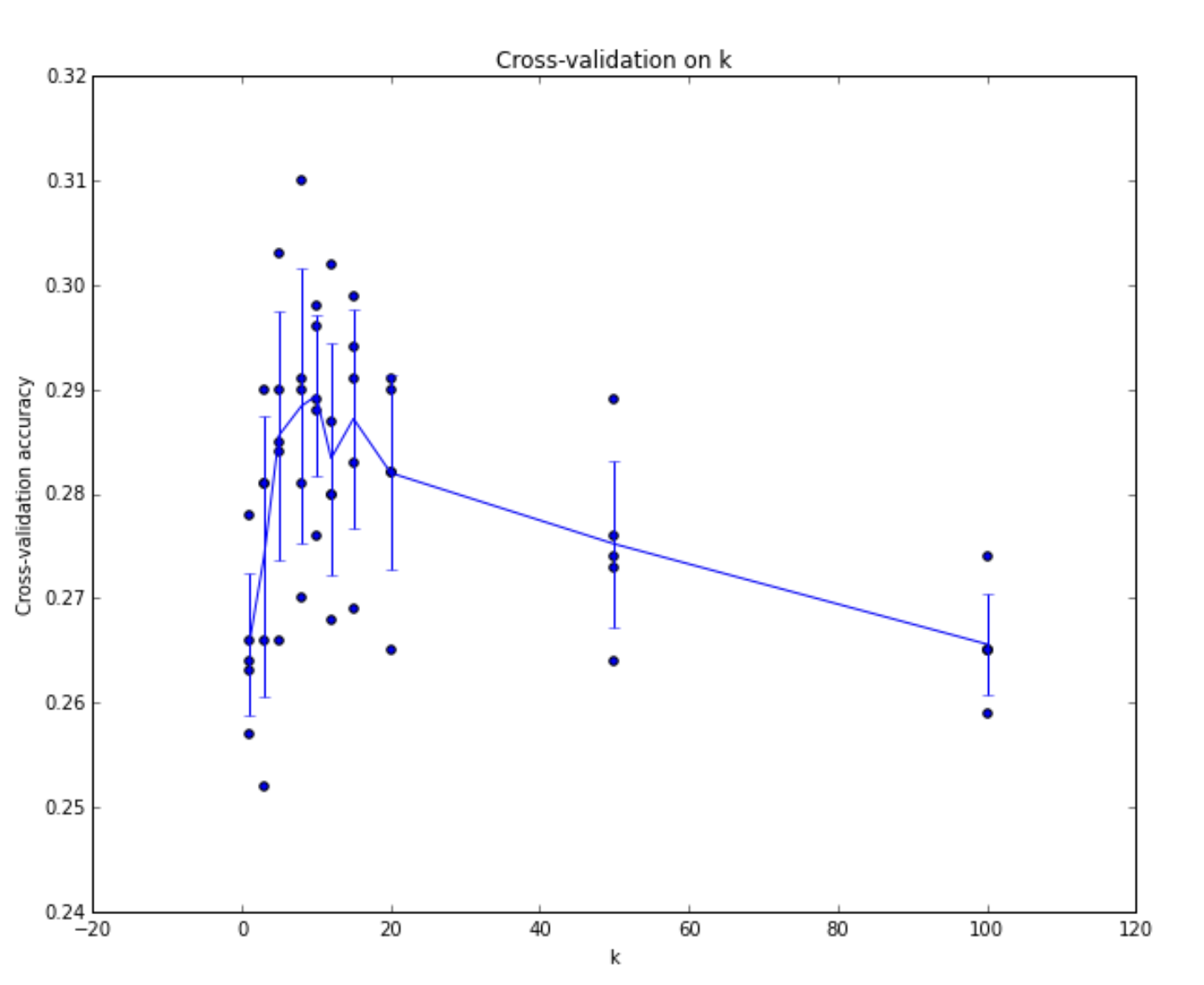
- Raw-pixel based L1/L2 distance is very counter intuitive, because of many realistically simple reasons.
- K-nearest Neighbours is very computational complex during test time, and very intuitive and easy and training time.
Copy-Notes
- If there are many hyperparameters to estimate, you should err on the side of having larger validation set to estimate them effectively.
- If you are concerned about the size of your validation data, it is best to split the training data into folds and perform cross-validation.
- If you can afford the computational budget it is always safer to go with cross-validation (the more folds the better, but more expensive).