Introduction
- Reinforcement Learning is learning how to map situations to actions so as to maximum a numerical reward signal
- Policy is a function that maps from state to action.
- There are two types of policies
- Target policy: Policy used to optimise the decision making.
- Behaviour policy: Policy used to take actions in the environment or policy used to navigate the environment.
- Off policy RL algorithms have different behaviour and target policies, they can be decouple the data collection and training.
- On policy RL algorithms have same behaviour and target policies. The agent takes actions and learns using the same policy.
Q-Learning is Off-Policy RL Algorithm
- Say that the agent is randomly choosing action to execute in the environment, ie, the behaviour policy is random.
- We will get Q value for (S, right), using Bellman equation
- Note that in the above equation, we are not taking the action a, it is selected based on our target policy. But it is not executed.
- For most off-policy algorithms,
- the target policy is greedy.
- the behaviour policy can be random, -greedy or greedy.
- This Q(S, right) observed on taking action, will be used to update our target policy using TD method.
- They can be decoupled, collecting data and learning our target policy, so Q-Learning is Off-Policy RL algorithm.
Q-Learning (off-policy TD control) for estimating
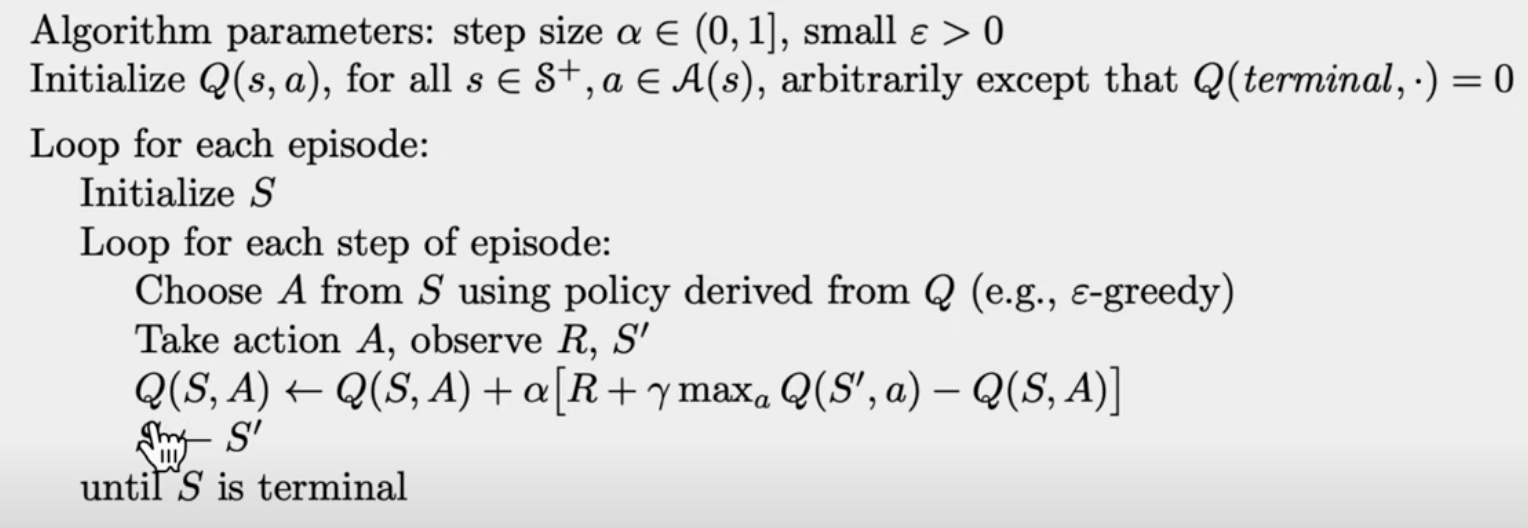
Sarsa (on-policy TD control) for estimating
